
- A+


将结构化数据添加到您的网站页面是极其重要的,因为丰富的结果将继续取代普通的旧蓝色链接。
在谷歌宣布Rich Results测试工具退出beta测试时,他们表示:
“丰富的搜索结果是在谷歌搜索中超越标准蓝色链接的体验。它们由结构化数据驱动,可以包括旋转木马、图像或其他非文本元素。在过去几年中,我们开发了富结果测试,帮助您测试结构化数据并预览丰富结果。“
虽然对该工具的改进是非常受欢迎的,并且有相当数量的工具和插件可以帮助生成结构化数据,但是仍然存在很大的差距。
将正确的结构化数据添加到网页仍然是一项手动工作,因为它需要使用代码,这很容易导致人为错误。
在这篇文章中,我将介绍一种相当先进的技术,它可以帮助生成无需手动输入的高质量结构化数据。
它依赖于计算机视觉的最新进展,并将完全不同学科的概念联系起来。
以下是我们的技术方案:
- 我们将利用一个产品页面截图的列表,我的团队注释了这些内容,如产品名称、价格、说明、主图像等
- 我们将把注释转换成googleautoml对象检测服务所期望的格式
- 我们将完成上传带注释的图像、培训和评估一个模型的步骤,该模型可以预测新截图上的注释
- 我们将在新图像上运行Python中的预测代码
- 我们将使用puppeter自动获取新的屏幕截图,并注入JavaScript代码将预测转换为结构化数据
- 我们将回顾一些使这项技术成为可能的关键概念
让我们先回顾一下一些基本概念。
计算机视觉101
学习和欣赏计算机视觉能力的最好方法是运行一个快速的例子。
我把一个简单的Colab笔记本放在一起,基本上遵循Streamlit的回购协议中概述的步骤。
请复制并选择Runtime>;Run all,以运行所有单元格。
最后,您应该得到一个动态的ngrok URL。
复制并粘贴到浏览器中,下载YOLO权重后,在侧栏中选择运行应用程序,您将看到下面的演示web应用程序。

这个网络应用允许你浏览不同的图像,并应用计算机视觉算法YOLO3,它代表你只看一次英文新闻稿服务。
你会注意到图片中感兴趣的对象(汽车、人等)是用彩色框表示的。
在计算机视觉中,这些被称为边界框,能够预测它们的任务称为目标检测。
与任何有监督的深度学习任务类似,目标检测算法需要标记的数据集。
用于对象检测的数据集包括图像和标签以及包含标签的框的坐标。
在图像中标记对象时需要一些繁重的手工工作。
幸运的是,由于我的业务不需要申请许可,我分享了已经由我的团队策划的200幅图片,您可以使用它们来完成本教程。
我们将学习如何将完整的数据集放在一起,以及如何自动缩放它,这样您就不需要手动标记每个图像。
用于图像捕获的浏览器自动化
在我早期的一篇专栏文章中,我介绍了让Chrome浏览器自动化的想法,以帮助我们在没有API的情况下执行重复的任务。
由于我们的想法是截取网页截图,并对图像应用对象检测以获取结构化数据,因此我们可以通过浏览器自动化实现部分过程的自动化。
给定一个产品URL列表,我们可以运行一个puppeter脚本(或者Python中的pyppeter)来打开所有的网页并将截图保存到磁盘上。
现在,仅靠截图是不够的。我们还需要每个结构化数据类型和边界框的标签。
至少有几种方法可以做到这一点。
第一个也是显而易见的方法是让数据输入人员/团队手动标记屏幕截图。
这是我们几年前开始尝试的方法。
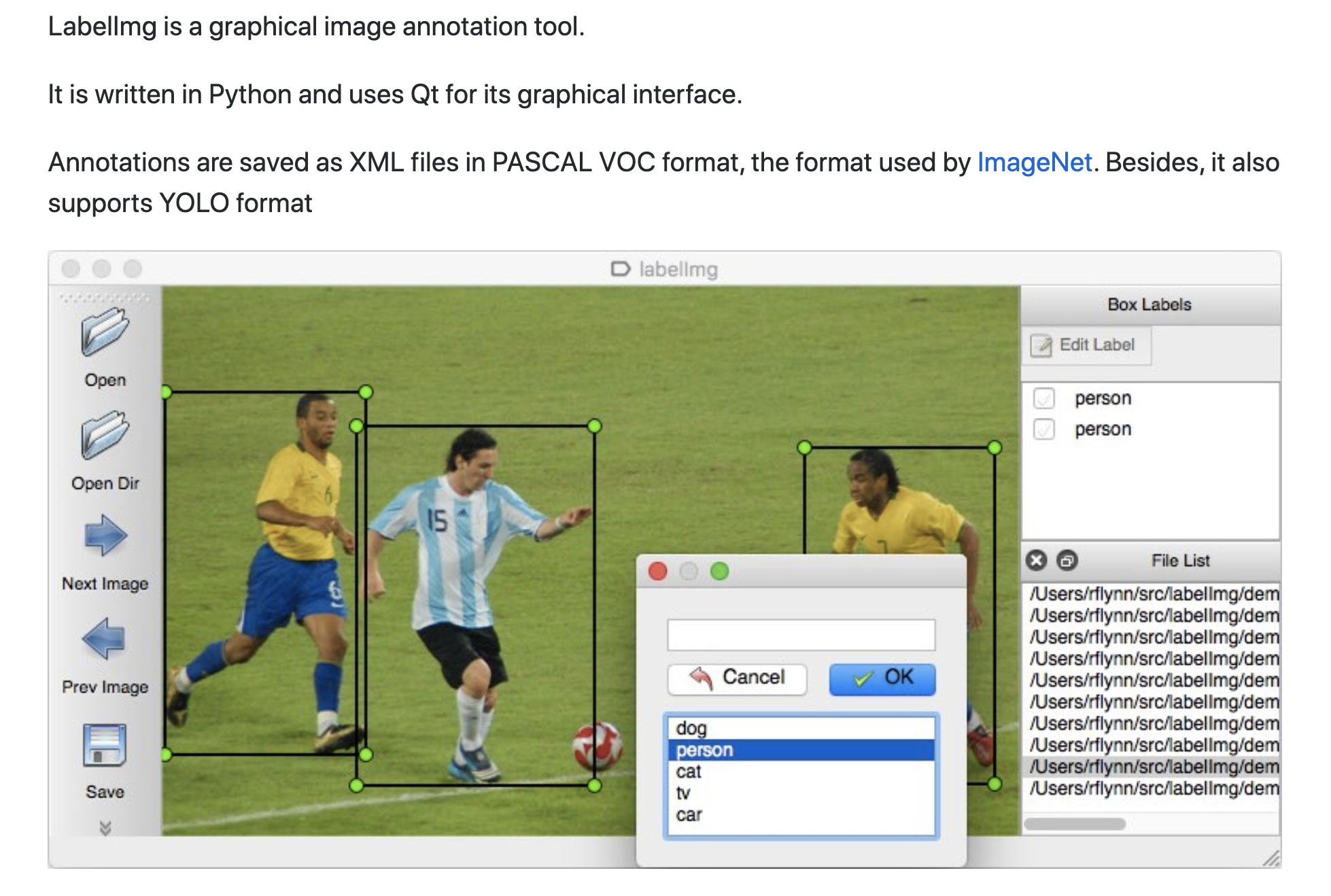
我们使用了一个名为LabelImg的开源工具,我们的数据输入人员手动在感兴趣的对象上绘制方框。
标签的结果以标准格式保存。在我们的例子中,我们使用了DetectNet格式。
这种格式为每个图像创建一个txt文件,每个对象都有一行。每行包括一个标签和坐标。
我们最近使用的另一种更具伸缩性的方法是截取已经有结构化数据的页面,并使用结构化数据来计算框的标签和坐标。
我们仍然将其与人工监督相结合,但主要是为了确保该过程产生高质量的培训数据。
用于视觉目标检测的Google AutoML
几年前,当我们第一次尝试这个想法时,我们不得不用非常艰难的方式来做!
实际上,我在2018年的TechSEO Boost演讲中曾简单地提到过这一点。
我在Coursera的深入学习专业学习期间学习了对象检测,并立即将这些点联系起来。
我们学会了使用YOLO,但在实践中,我发现更快的RCNN是当时性能最好的谷歌网络推广方法。
Tensorflow对象检测API使事情变得简单了一些,但远没有AutoML那么简单。
当使用AutoML时,我们只需要提供预期格式的数据,并为每个标签/边界框提供足够的示例。此时,服务只需要10个。
我们必须得到数百个每个标签的例子,以获得体面的性能。
既然我们了解了基本原理,我们就开始工作吧。
为AutoML准备数据集
让我们回顾一下产品数据集中的一个例子。每个图像都有两个文件。
第一个文件是图像本身,如下图所示。
可以使用以下Python行在googlecolab中显示它。
第二部分是相应的带有标签的DetectNet文本文件。
您可以使用命令行查看它。
!目录号imag1063.txt
屏幕截图中的每个标记对象都有一条线。该线包括标签名称和边界框坐标。
让我们看看当我将这个特定的示例加载到AutoML中时它是什么样子的。
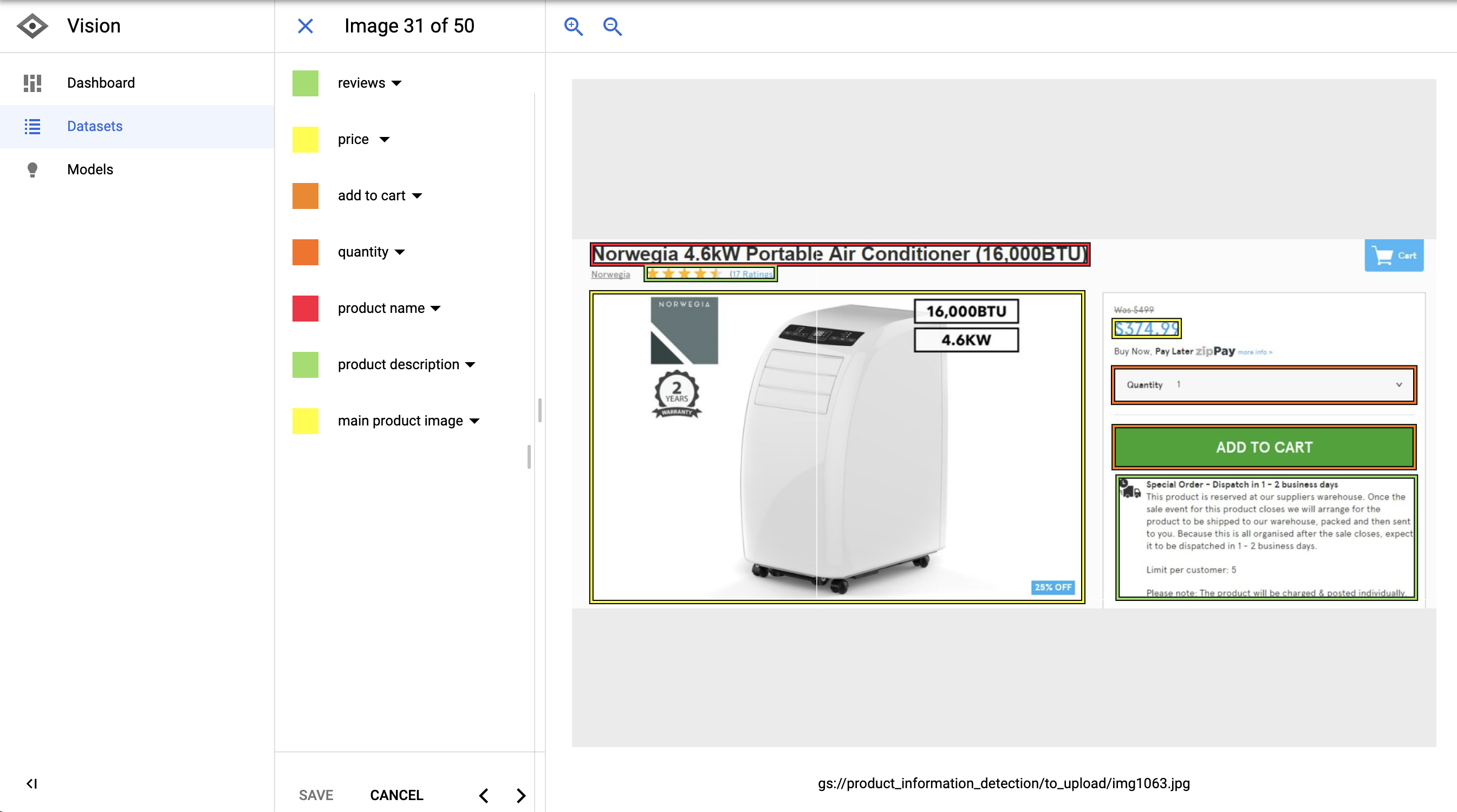
您可以看到结构化数据元素是如何用边界框仔细标记的。
我们有产品名称、价格、数量、评价、描述等。
在上传示例之前,我需要将它们转换为AutoML所期望的格式。
我还需要将图片上传到Google云存储桶中,但这部分很简单。
格式为:set,path,label,xu min,yu min,,,xu max,yu max
首先,我从磁盘读取文件并创建了一个字典列表,每个边界框一个。
在这里,您可以看到每个边界框/对象有多少个示例。
下面是一个示例:
如果你仔细观察,文件中的坐标是整数,而不是小数。AutoML期望这些数字规范化为1。
你可以用数字除以图像的宽度或高度。
一旦我们有了具有正确值的数据结构,我们就可以继续将其保存到具有预期格式的CSV文件中。
这将生成一个如下所示的文件。
这需要一点点的工作和对概念和过程的清晰理解,但是我们已经准备好训练我们的预测模型了。
将CSV下载到您的计算机并上传到Google云存储桶中。
在AutoML中训练我们的预测模型
首先,让我们创建一个新的数据集来导入我们在云存储中标记的图像。
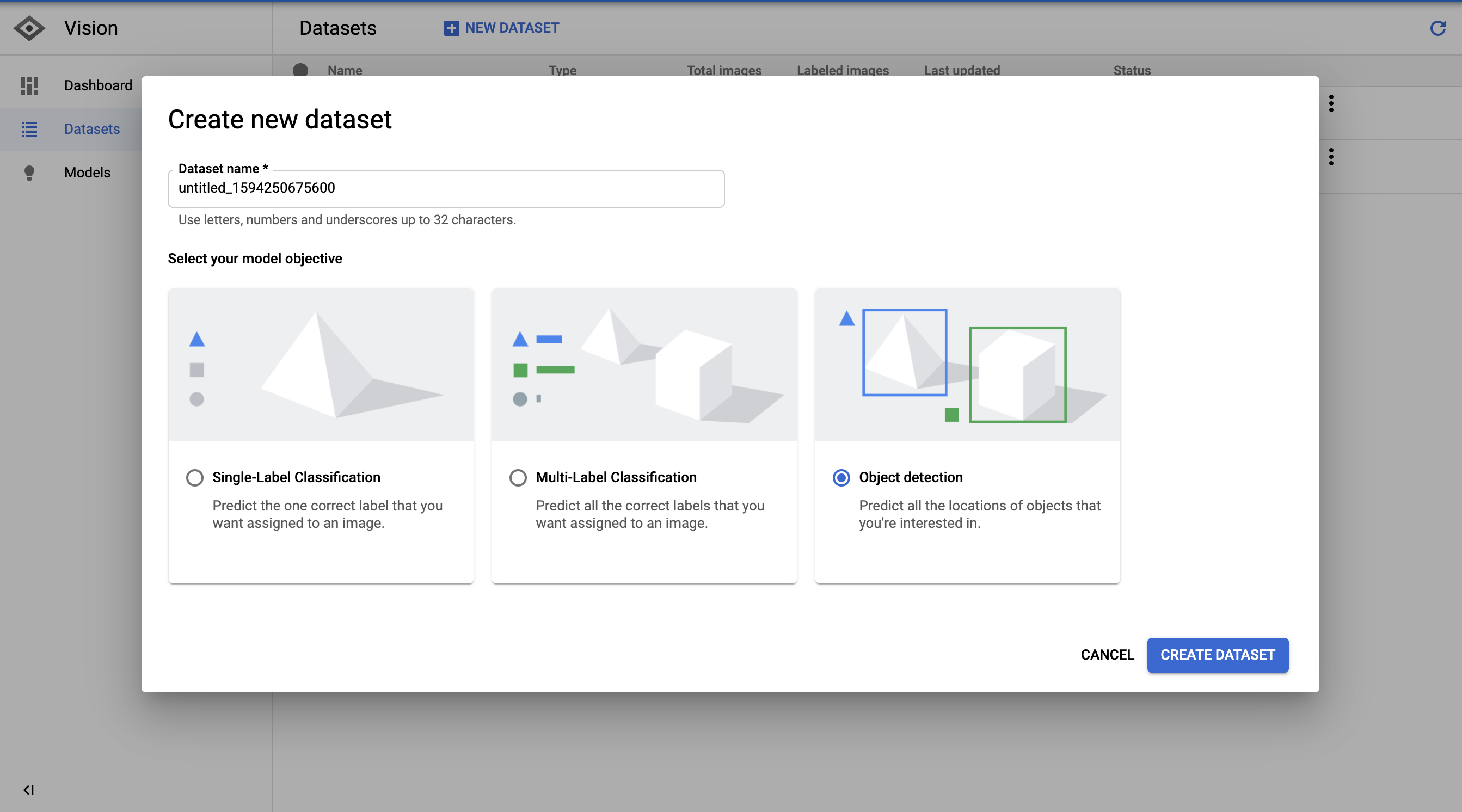
接下来,我们选择用图像路径、标签和边界框坐标生成的CSV。
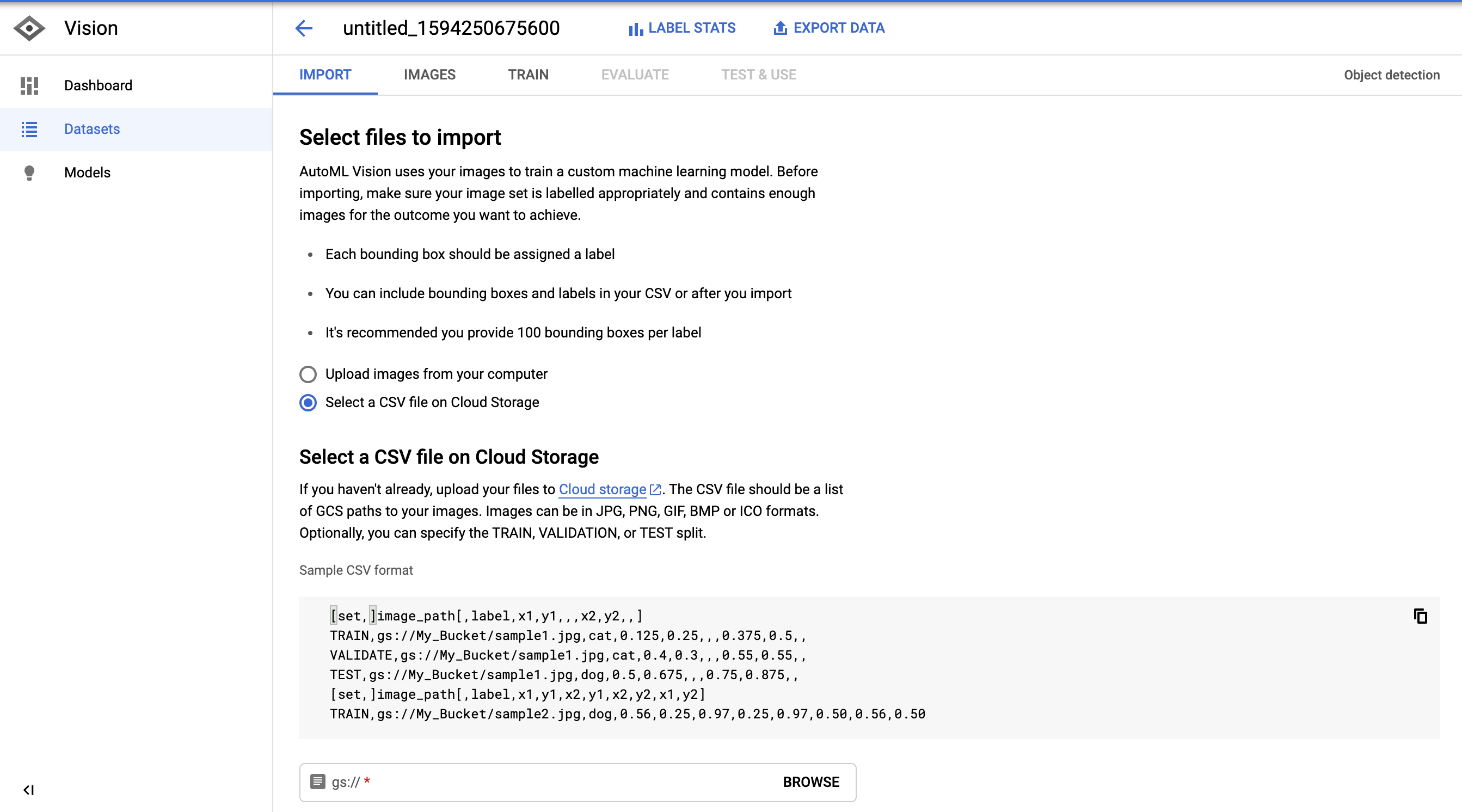
导入图像后,AutoML创建了一个非常好的图像浏览器,可以用来查看图像和标签。

最后,在我们训练了几个小时的模型之后,我们得到了非常高精度的度量。
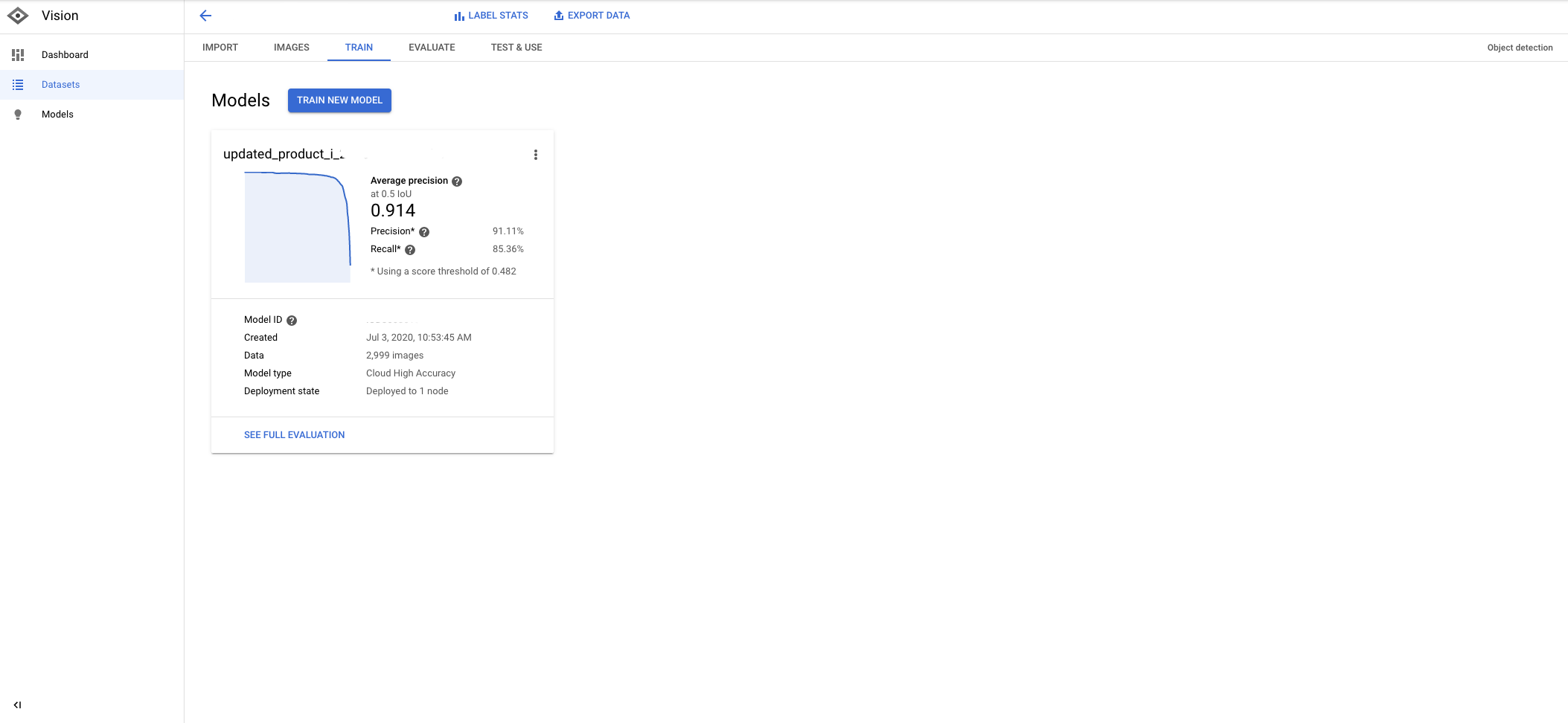
为了测试模型,我手动拍了一张梅西产品页面的截图,并将图片上传到模型预测工具中。
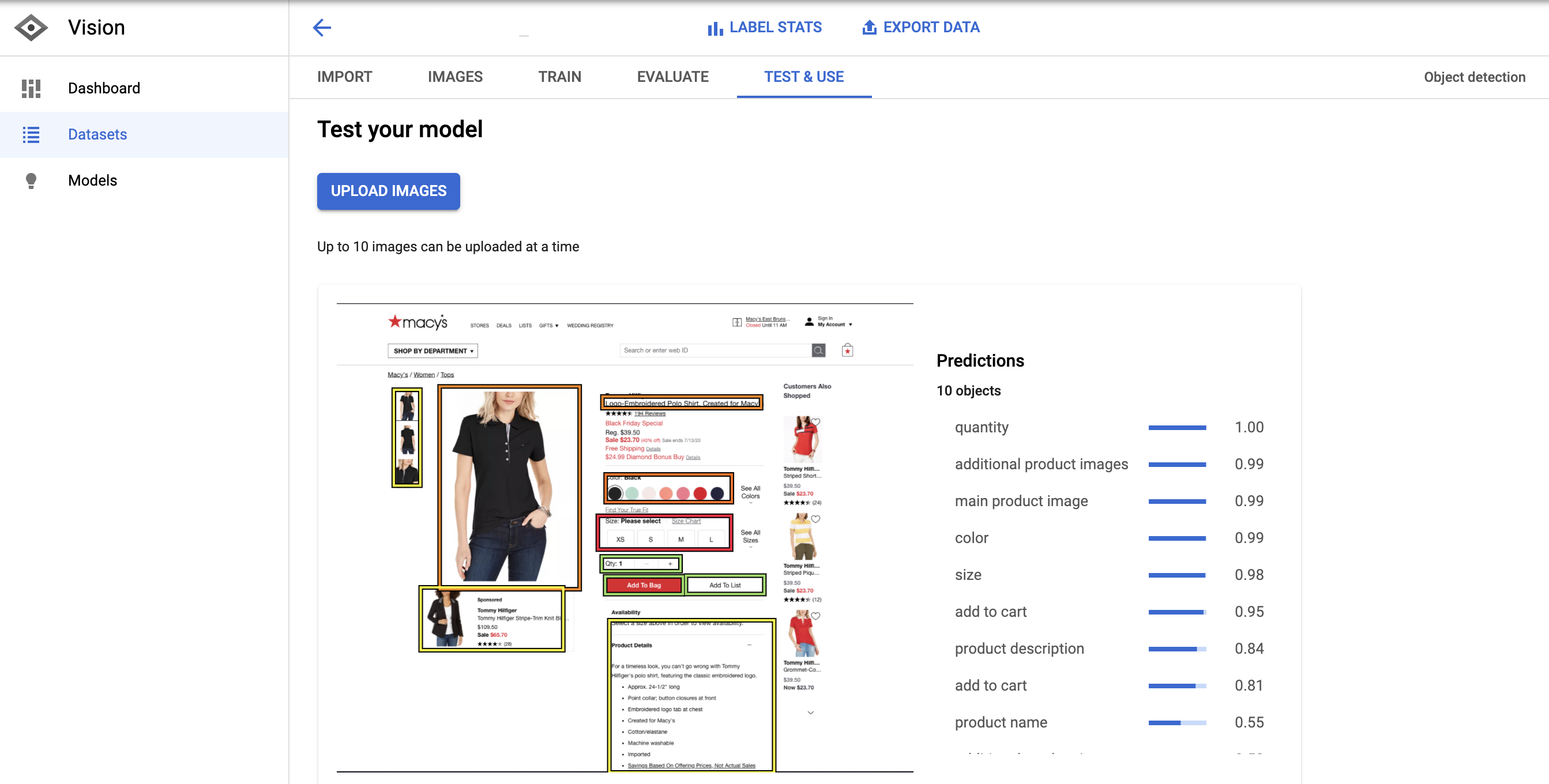
这些预测非常好。这个模型只是错过了评论和价格。
这意味着这个例子具有较高的精确度和较低的召回率。
我们可以通过增加标有价格和评论的例子来改进它。
我们的评论较少,但有很多价格示例。可能不是,但这个价格不合适。
下一部分可能是最有趣的。
我们如何将这些边界框坐标预测转化为可以注入HTML的结构数据,
将边界框预测转化为结构化数据
首先,需要从Python自动截图。我们可以用Pyppeeer来做这个。
为了在Colab中工作,我们需要安装chromedriver
在Jupyter或Colab中运行异步函数可能很痛苦,所以我更喜欢将它们作为脚本运行。

这是从我们的模型中得到预测的代码。
此代码要求创建一个访问AutoML服务的服务帐户。
这条线将根据我们拍摄的屏幕截图生成预测。
让我们在亚马逊产品页面上查看我们的模型预测。
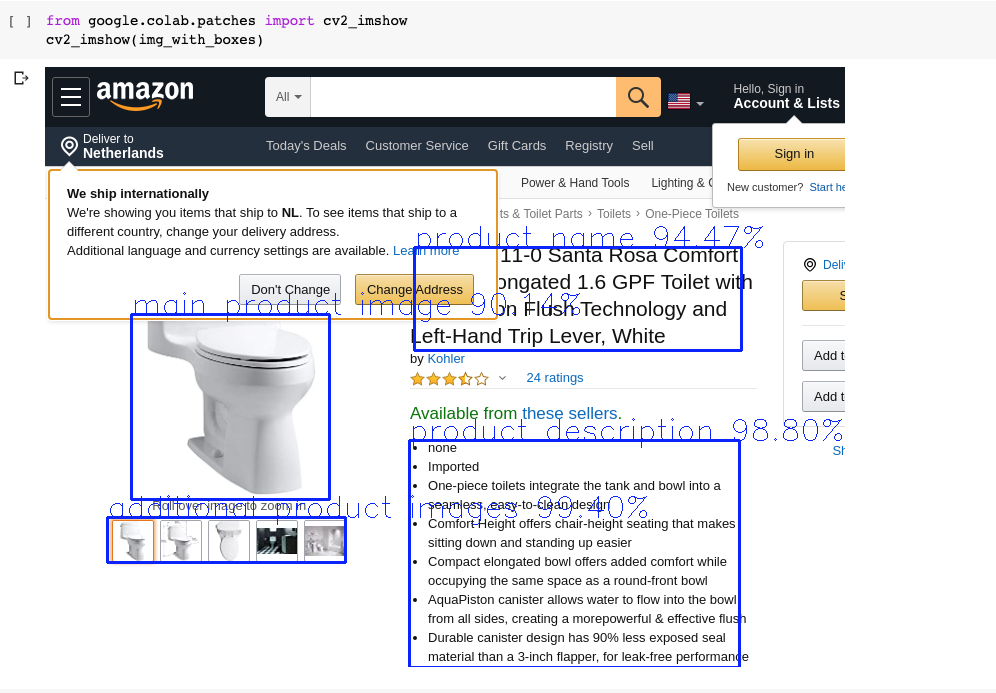
看看这个模型是如何检测到产品名称的,即使弹出窗口部分地阻碍了它。
相当令人印象深刻!
为了绘制方框和标签,我创建了一个函数,该函数从AutoML模型获取图像文件名和响应。你可以在这个要点中找到它。
那就用这些台词来称呼它。
我还打印了我们得到的预测。
然后,我们可以在这里把它们形象化。
现在我们进入棘手的部分。
让我们使用产品描述的预测坐标,上面用粗体突出显示。
我要计算边界框正中间的一个点。我们可以使用:
我们可以识别JavaScript中出现在这些坐标中的htmldom元素。
森摩尔网络从2013年开始做外贸网站的SEO推广服务,到现在已经7年多了。我们已经为上千个人和企业提供外贸网站的优化推广服务,客户遍及全国各地,我们的服务深受客户好评!如果您有外贸网站需要推广,请联系我们,我们会提供专业、快速的额服务!








