
- A+


可以毫不夸张地说,google rank brain是搜索结果确定方式的一次革命。
1996年,将链接作为排名信号的想法,彻底改变了搜索,后来成为googlepagerank。
过去十年的搜索市场份额
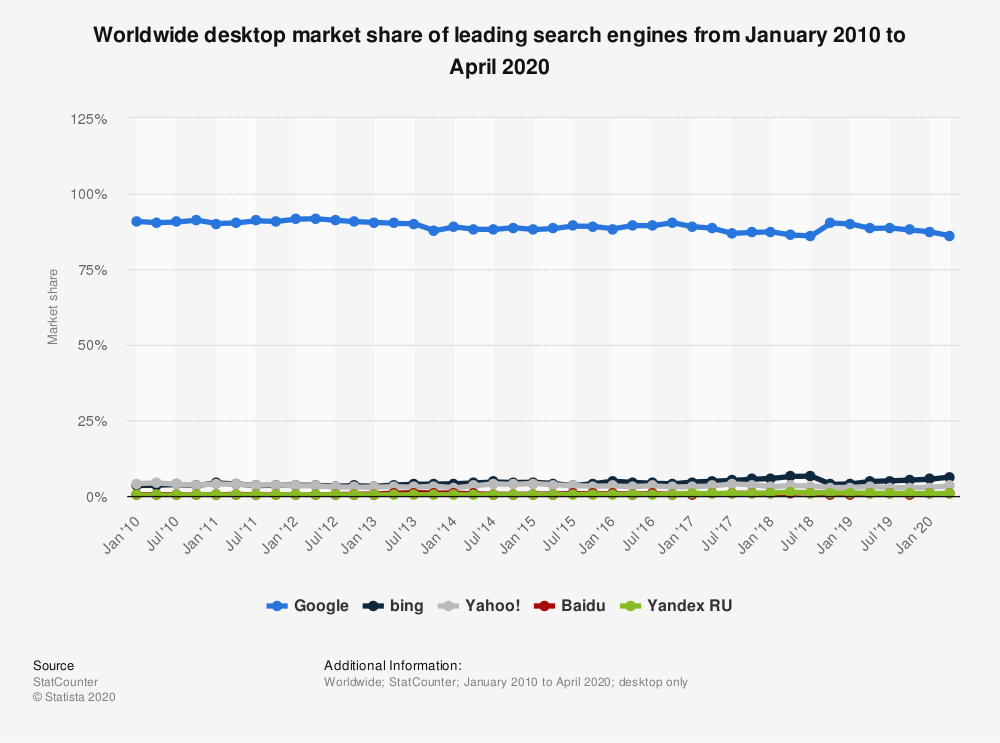
从那以后,已经发生了很多事情,并且外贸网站搜索引擎优化引入了很多大规模的调整和算法,但是可以说没有一个比Rank Brain更重要。
正如我们将在下面讨论的,这不仅仅是由于它对结果的影响(尽管它也可以说是在那里获胜),而是因为它的意思是机器学习第一次被引入到我们所认为的搜索中。
在此之前,机器学习已经在Google新闻中使用过,但是没有像我们在RankBrain中看到的那样。
所以,这很重要。这是革命性的。这是机器学习在搜索中的引入。
但是…
什么是兰克布雷恩
Rank Brain是一个系统,通过这个系统,谷歌可以更好地理解用户搜索查询的可能意图。它于2015年春季推出,但直到当年10月26日才公布。
在一开始,Rank Brain被应用于谷歌以前从未遇到过的查询,这些查询在当时和现在都占到了搜索总量的15%。它从那里扩展到影响所有的搜索结果。
其核心是,Rank Brain是一个建立在蜂鸟基础上的机器学习系统,蜂鸟把谷歌从一个“弦”环境带到了“东西”环境。
这就是说,它是从“阅读”字面字符,而不是“看到”他们所代表的实体。
关于实体与字符串之间的关系
为了说明这一重要的进步及其在Rank Brain中的作用,我们需要简单地考虑一下构成我的一个同伴和朋友名字的人物:
“杰森·巴纳德”
在Hummingbird之前,Google看到了这些字符以及2个单词和13个字符的集合,这些字符按顺序排列,并且经常在页面上使用,这将使它与搜索字符串“jasonbarnard”相关。
可能是杰森真的,那没关系。
他们依靠链接和其他一些信号,来显示最“相关”的信号,而不了解Jason是谁或什么。
有了蜂鸟,我的朋友不再是简单的字符集合,而是变成了实体:
/g/11cm_q3wqr
这家伙的机器ID是:

本例中的机器ID是Google分配给实体的字母数字序列。
在本文中,我们不能深入研究实体,尽管您可以在这里阅读它们。
简言之,Hummingbird是RankBrain正常运行所必需的,但它却让谷歌看不到这句话:
“Jason Barnard是Dave Davies的朋友,他喜欢红衫军,是一名数字营销人员。”
并简单地将其解释为一系列要根据查询进行排列和权衡的字符。
虽然很高级,但基本上还是有人在回答这个问题:“jasonbarnard”在文本和链接中出现了多少次,
假设这个查询又是“jason barnard”,而Hummingbird的这句话在Google看来更像:
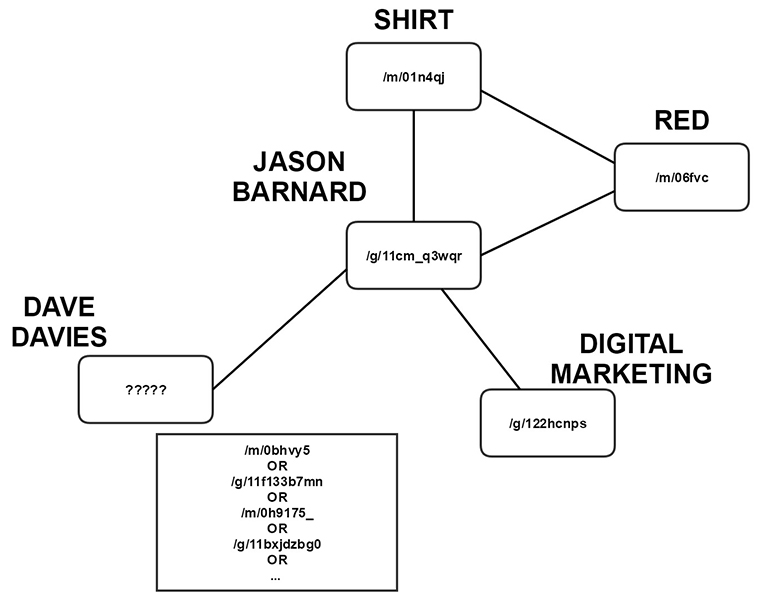
每个核心实体由一个机器ID表示。
这些ID对每个ID都是唯一的,并且没有两个实体具有相同的ID。
我并不是故意加在句子里的。
我的名字很普通,还有比我更出名的“戴夫戴维斯”(dave davies)(我知道,我知道…很难相信)。
谷歌将通过页面上的其他实体和网络上的其他连接得到澄清。但那是另一个故事,英文新闻稿服务。
在RankBrain的背景下,需要知道的是,有了蜂鸟,Google(/m/045c7b)现在把世界理解为一个事物的集合,而不是字符串。
回到兰克布雷恩
有了这些关于实体的信息,我们就可以回到兰克布雷恩。
RankBrain的核心,可以看作是一个预筛选系统。
当一个查询被输入到Google中时,搜索算法会根据您的意图匹配查询,从而以最佳的格式呈现出最好的内容。
但是如果谷歌不知道你的意图,
谷歌为什么要引进兰克布雷恩
RankBrain最初推出是为了满足一个简单但又大的问题。
谷歌没有看到有15%的查询被使用,因此没有上下文,也没有过去的分析,以确定他们的结果是好还是不满足用户的意图。
输入RankBrain。
这个系统将检查事物而不是字符串。
RankBrain还将考虑环境背景(例如,搜索者的位置)并推断出在哪里做过的含义。
这可能是一个简单的理解过程,语序可能是搜索过程的函数,而不是意图。
我们当中有谁没有通过简单地加上一两个词来改进查询呢。
在我进入谷歌之前,谷歌肯定已经看到:
“维多利亚披萨”
但是,当我没有取回我想要的产品组合时,我可能会开始添加条款,从而导致查询更像:
“披萨维多利亚bc薄皮蔬菜”
很有可能Google没有看到这个特定的查询,但是因为他们关注的是事物而不是字符串,所以他们知道这个查询可能与以下类似,即使不一样:
“维多利亚薄皮素食披萨”
“薄皮蔬菜披萨在我身边”
或者用声音:
“好的谷歌,我在哪里可以买到薄皮素食披萨,”
RankBrain是怎么工作的
不出所料,谷歌从未具体描述过RankBrain是如何运作的。
尽管如此,我们可以对幕后发生的事情做出一些有根据的猜测。
新建搜索功能
如上所述,我们需要停止用我们所理解的方式思考,开始像机器一样思考。
我可能会看到:
“维多利亚披萨”
谷歌认为:
/m/0663v/m/07ypt
这使事情发生了巨大的变化。“维多利亚bc”不是两件事,而是一件事。
比较其他位置时:
“披萨”“位置”
他们可以推断:
/m/0663v/m/07ypt(维多利亚披萨)
可能与:
/m/07ypt/m/0663v(维多利亚bc披萨)
基本上,因为他们知道实体是如何运作的,所以他们可以超越查询,深入到意义。
公共实体
如上所述,他们将使用的核心机制之一是实体识别。
如果他们知道一个查询包含的实体与他们以前见过的另一个查询相同,而几乎没有限定符(例如在关于音乐会的查询中从“where”更改为“when”),那么这将表明结果集可能是相同的、高度相似的,或者至少是从相同的url短列表中提取的。
前10名
在他们2013年的专利“使用非结构化数据中的实体引用进行问答”中,谷歌描述了一种他们可以:
- 实体提交自己的索引
- 回顾前10名中的实体
- 从中推断出他们期望相互关联的各种实体,并对查询进行顶部回答
例如,如果Google看到Jason的ID和我的ID经常同时出现,那么他们就能够将这两者连接起来。
如果是杰森和那个讨厌的怪人一直为我的名字排名…那么他们会得出结论,那就是戴夫戴维斯。
类似地,如果他们看到排名为Jason名字的页面上也有一组公共的实体,那么他们可以假设Jason的完整数据包含这些信息,而忽略那些没有这些信息的页面。
监控
记住这是一个机器学习系统。
其固有的功能是确定、测试、跟踪和调整。
基本上,系统将在考虑成功指标的情况下查看查询。
然后,它将调整它对不同信号的权重以及它所偏爱的信号,然后监控是否成功。
不会逐个查询执行此操作。
记住,这个系统是为了解决Google以前从未遇到过的查询问题而推出的,通常会有一些无法自己监控的单词或是少量单词。
森摩尔网络从2013年开始做外贸网站的SEO推广服务,到现在已经7年多了。我们已经为上千个人和企业提供外贸网站的优化推广服务,客户遍及全国各地,我们的服务深受客户好评!如果您有外贸网站需要推广,请联系我们,我们会提供专业、快速的额服务!
- 我的微信
- 这是我的微信扫一扫
-

- 我的微信公众号
- 我的微信公众号扫一扫
-







